很久没看过360的站长平台了,于是在360搜索中site了一把,发现居然安全评分是99,而不是100。好奇点进去看了下,发现下面这个大奇葩:
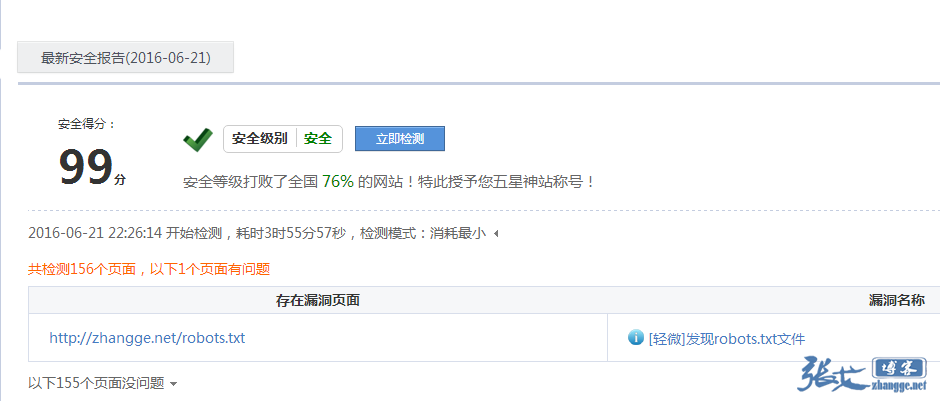
呐尼?发现robots.txt文件?这也算漏洞?继续看了下解释:
大概是懂了,就是robots会泄漏网站后台或其他敏感地址,我之前遇到不想让人通过robots知道的地址,我也会使用上述解决办法中的第3条,只写局部字符串。
- 漏洞类型:
- 信息泄露
- 所属建站程序:
- 其他
- 所属服务器类型:
- 通用
- 所属编程语言:
- 其他
- 描述:
- 目标WEB站点上发现了robots.txt文件。
1.robots.txt是搜索引擎访问网站的时候要查看的第一个文件。
- 收起
2.robots.txt文件会告诉蜘蛛程序在服务器上什么文件是可以被查看的什么文件是不允许查看的。举一个简单的例子:当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。同时robots.txt是任何人都可公开访问的,恶意攻击者可以通过分析robots.txt的内容,来获取敏感的目录或文件路径等信息。
- 危害:
- robots.txt文件有可能泄露系统中的敏感信息,如后台地址或者不愿意对外公开的地址等,恶意攻击者有可能利用这些信息实施进一步的攻击。
- 解决方案:
- 1. 确保robots.txt中不包含敏感信息,建议将不希望对外公布的目录或文件请使用权限控制,使得匿名用户无法访问这些信息
2. 将敏感的文件和目录移到另一个隔离的子目录,以便将这个目录排除在Web Robot搜索之外。如将文件移到“folder”之类的非特定目录名称是比较好的解决方案: New directory structure: /folder/passwords.txt/folder/sensitive_folder/
New robots.txt: User-agent: * Disallow: /folder/
3. 如果您无法更改目录结构,且必须将特定目录排除于 Web Robot 之外,在 robots.txt 文件中,请只用局部名称。虽然这不是最好的解决方案,但至少它能加大完整目录名称的猜测难度。例如,如果要排除“admin”和“manager”,请使用下列名称(假设 Web 根目录中没有起始于相同字符的文件或目录): robots.txt:
User-agent: *
Disallow: /ad
Disallow: /ma
原文地址:http://webscan.360.cn/vul/view/vulid/139
但是,这些完全是掩耳盗铃的做法,明眼人都能轻松识别博客是WordPress还是其他建站程序,什么敏感目录根本没法隐藏,当然隐藏了也没啥用。
不过,看到不是100分就不爽,所以我也掩耳盗铃的解决一下吧!
我的思路很简单,对于非蜘蛛抓取 robots.txt 行为一律返回403,也就是robots.txt 只对蜘蛛开放。实现非常简单,在 Nginx 配置中加入如下代码即可:
#如果请求的是robots.txt,并且匹配到了蜘蛛,则返回403
location = /robots.txt {
if ($http_user_agent !~* "spider|bot|Python-urllib|pycurl") {
return 403;
}
}
加入后reload以下Nginx,然后再到浏览器访问robots地址,应该能看到禁止访问403了。
随即去360扫描了一把,结果并不意外:
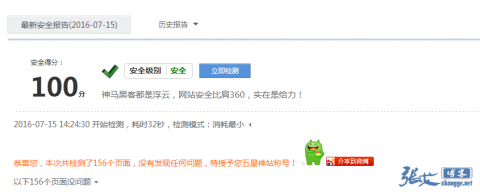
转载请注明出处 AE博客|墨渊 » 简单修复360安全检测提示的发现robots文件漏洞
发表评论